
Application logs are one of the most useful diagnostic aids in platform support and it pains me that many developers often ignore such a critical aspect of their system.
When To Not Log
There is only one reason for an application to not generate any logs, and that is for performance reasons, e.g. constrained telecoms or web servers running at maximum IO capacity where even writing to disk will have an impact on application performance.
And even then, you can bet those applications catch and log exceptions at an ‘error’ level for diagnostic purposes.
Really, there are no reasons for an application to not generate any logs ever, which is something I see all too frequently.
Logs Are Important
The developer might know what the application is doing already, they wrote it, but logging also tells other people what the application is doing. The QA team, the systems team responsible for deployment, the on-call sys admin who is responding to alerts generated by a failing system, running the code, at 2am. All these people need to understand what the code is doing, the developer is part of a team and the code is part of a system. Everyone and everything has to work together for the solution to function.
It’s Hard To Log Too Much
Most languages have third party libraries to help with logging, e.g. log4j, WinstonJS, etc.
These libraries let you configure a log level, e.g. debug, info, warn, error, none, depending on the severity of what you are logging, so you can filter what the application actually spits out.
e.g. if you consider the following code
logger.debug('User not authenticated', email);
logger.error('Exception', err.message);
an application configured to log at debug level would log both lines, but an application configured for just error logging will only log the on error line. This way you can run the application at a log level suitable for your needs.
router.post('/signin', async (req, res, next) => {
logger.debug('router.post /signin');
try {
}
}
It’s even reasonable to add logging at the top of each function call, so you can trace through the application as it runs confirming the correct parts get called. In the worst case it’s comfort noise, in the best case it will help someone solve a bug as they step through the logs later.
Catch And Log Your Exceptions
When your application generates an exception that means it’s doing something you didn’t predict. Probably triggered by an error.
It takes reading documentation to know what libraries and functions will and will not throw exceptions. A good rule of thumb is if the libraries’ example code catches exceptions, production code should also catch those same exceptions.
A responsible developer will catch and log these errors every time and these errors should be logged at the appropriate error level.
Log To Console/Disk
Depending on your application and it’s environment it is not enough to just return an error as the result of a request, e.g. in the case of a web server.
Creating a web service that returns an HTTP 500 status code and some JSON containing the error to the client seems a reasonable way of handling errors but it offers no paper trail. If your application can’t log people in because a disk is full, with out proper logging how are you going to know when the incident started? How are you even going to know it’s because the disk is full if you aren’t catching, throwing and logging exceptions around that code? How is the systems administrator supposed to diagnose that issue at 2am when text messages get them out of bed?
Logging to disk gives you the benefit of 20/20 hindsight. With correct use of timestamps you can see when issues occurred and from that come up with holistic solutions to stop them from happening again.
Logging to console gives you something to look at if the disk fills up.
Use A Log Aggregator
Logging isn’t just for developers and systems administrators, it also a useful information source for first tier customer support when the logs are pumped in to an aggregator.
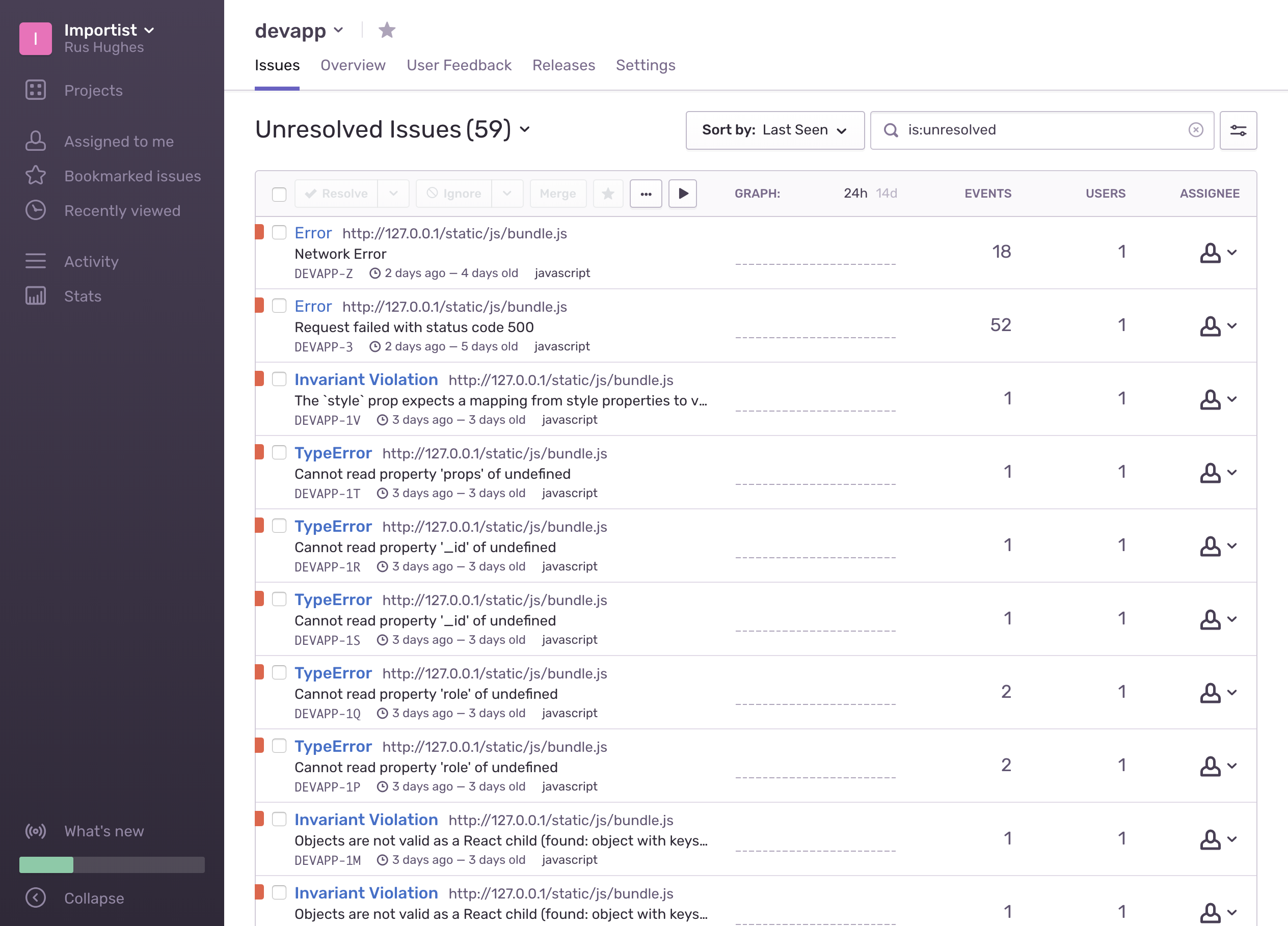
With Importist we are using Sentry, it has an open source solution if you want to host your own or a hosted option with a usable free tier, other options include Splunk or Kibana.
To a certain extent, anyone that can read should be able to understand some error messages. e.g. Cannot connect to database. Allowing first tier support read access to a good log aggregator will reduce the cost and time to fix of incidents by helping them diagnose customer service issues themselves and improve the quality of bug reporting, removing any guess work from second tier support and beyong allowing them to get to the heart of the issue quicker.
A good log aggregator will also integrate with Slack and email for reporting and notification, possibly alerting you to issues before your customers even realise there’s a problem if configured correctly.
You Can Graph Logs
Logs can be used to create graphs. Key Performance Indicators (KPIs) and statistics can be monitored by analysing logs with a tool like Munin. A great example is the Apache web server. Apache will log every HTTP request to an access file with a timestamp. Analytics tools like Munin can then scan that log file to calculate statistics like accesses per second.
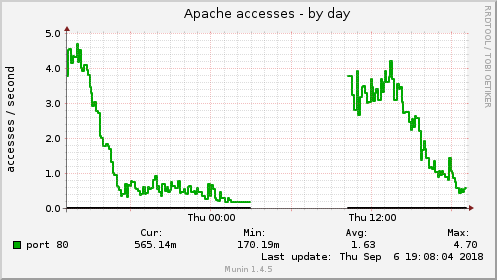
I’m currently investigating Logz.io for visualising our system logs. Logz.io makes logging cool again as you can run pattern matching against the log output of every component in your system, the application servers, the databases, the web servers, email servers, everything. Properly configured tools like Logz.io or ELK will even generate access maps if the user’s IP is available.
The Dangers Of Courses
I’ve seen a lot of people wanting to get started in software development take courses or bootcamps thinking that is enough and then they will know it all.
I’m a big fan of self education and am slowly going through a series of courses on Udemy for fun. I also love what the freeCodeCamp guys are doing. But all these courses seem to have one thing in common so far.
None of them discuss logging.
Well, that’s not entirely fair, freeCodeCamp uses logging as an example of writing Express middleware. But so far that’s it and that’s really not good enough.
Not All Of This Is Gospel
How and the amount you log obviously depends on what you are doing and who you are working with.
If you’re writing a quick script to parse a CSV you will require a different level of logging than if you’re dealing with a distributed application spanning many processes and servers.
If you’re part of a company then you will need to log appropriately for the rest of the company to function.
Conclusion
Depending on your point of view logging
- makes the terminal messy
- helps diagnose system and performance failures
- can be used to monitor system performance
- can be used to create system KPIs